こんにちは。中山です。
Kafka(Apache Kafka)は、複数台のサーバで大量のデータを処理する、分散メッセージングシステムです。
一般的に、Kafka というと、ログ収集ですとか、IoT におけるデータハブとして使われる場面が思い浮かびます。
しかしこの Kafka、近年話題のマイクロサービスとも、相性が良いそうです。
Kafka とは
Kafkaは、複数台のサーバで大量のデータを処理する、分散メッセージングシステムです。
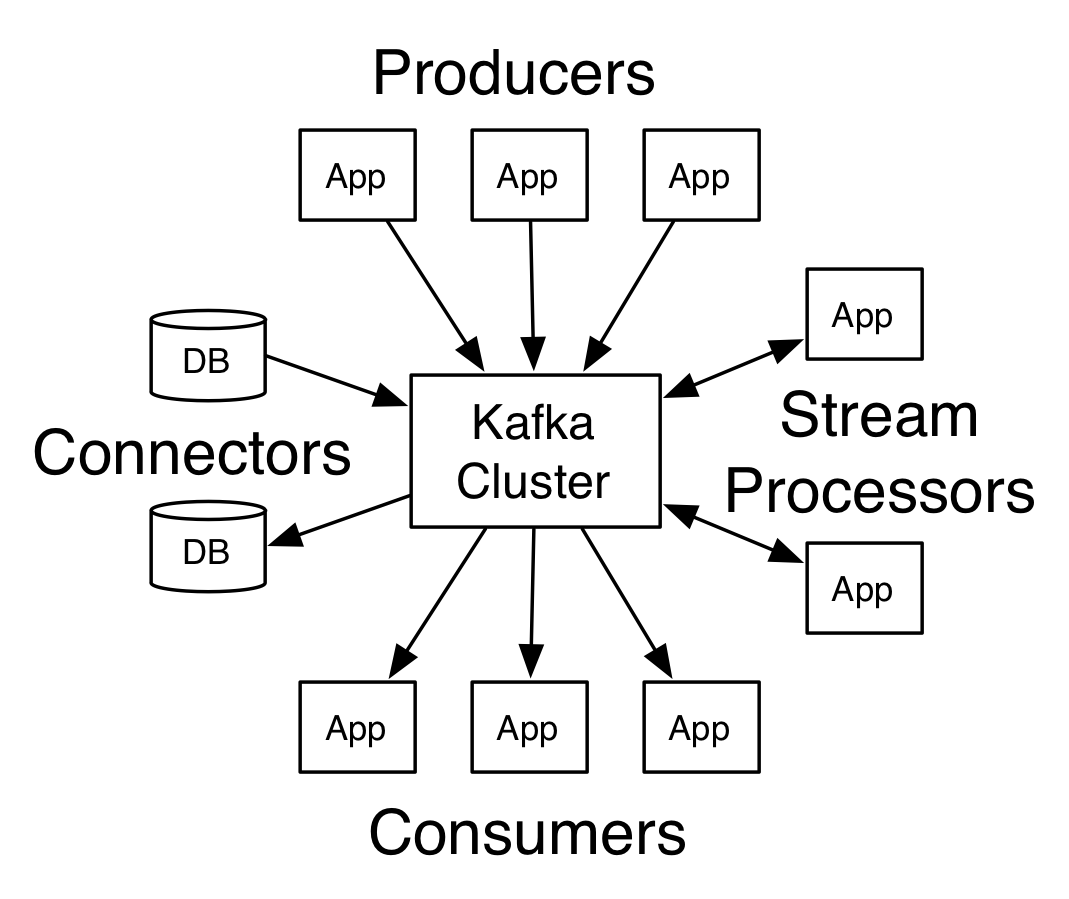
Apache が提供する、オープンソースのコミュニティ版のほか、Confluent などのサードパーティ製ディストリビューション、また、AWS が提供する、マネージド Kafka サービス(Amazon MSK)などもあります。
今回は、コミュニティ版の Apache Kafka を利用します。
また、Kafka 自体の詳しい説明は、当記事では割愛します。( Apache Kafka の Quickstart などをご参照ください。)
マイクロサービスと Kafka
マイクロサービスとは、AWS の説明によりますと
マイクロサービスは、小さな独立した複数のサービスでソフトウェアを構成する、ソフトウェア開発に対するアーキテクチャ的、組織的アプローチです。各サービスは、正確に定義された API を通じてやり取りします。
とのことです。
たとえば、あるサービスA が、サービスB、サービスC と連携して稼働しているパターンは、以下のように表すことができるでしょう。

しかし、サービスが次第に増えてきますと、サービス間の連携の関係が、非常に複雑になってしまう可能性も出てきます。

マイクロサービス化したのはいいけれど、こんなにごちゃごちゃになってしまっては大変です。
そうだ、Kafka が、このピンチを救ってくれはしないだろうか?!
・・・はい。Kafka、救ってくれそうです。ここに Kafka を組み込んでみますと、たとえば以下のようなイメージになります。

つまり、サービスA とサービスB 、また、サービスA とサービスC とで、これまで直接やりとりしていたデータを、それぞれ、Kafka を経由してやりとりする、という形になります。(正確には、Kafka が提供する、Producer、Consumer、Broker や Topic の仕組みを利用して、データのやり取りを実現します。)
このような構成にすることで、以下のようなメリットが生まれます。
- データを送信するほうのサービス、データを受け取るほうのサービスともに、接続対象となるモジュールを 1つに限定することができる(データを送信する側、受け取る側ともに、Kafka とだけ接続しておけば済むようになる)
- データを送信するほうのサービス、データを受け取るほうのサービスのスケールアウトに柔軟に対応できる(データを送信する側、受け取る側ともに、Kafka に対してだけデータ送受信することで、お互いの増減に影響を受けなくなる)
- データを受け取るほうのサービスがダウンしていたとしても、Kafka がそのデータを保管し、サービス復旧後に再送したりすることもできる
つまり、それぞれのサービスのあいだに Kafka が介在することで、変更に強いアーキテクチャを構成することができる、と言うことができるでしょう。
問題点
一見万能に見える、この kafka 介在のパターンですが、しかし、ひとつ大きなデメリットがあります。
前述の図をよくご覧いただくとお気づきになるかもしれませんが、そうなのです。このパターンでは、サービスA は、サービスB、またはサービスC からのレスポンスを受け取ることができないのです。

基本的に、Kafka を介した
- Kafka の Producer が、 Kafka の Broker にある Topic に Message を送信
- Kafka の Consumer が、Broker の Topic に格納されている Message を取得
という処理は一方通行で行われるため、このままでは、データを送信する側であるサービスA は、データを受け取る側のサービスB やサービスC からのレスポンス(処理結果などを表すデータ)を受け取ることができません。
Saga パターンによる解決
この問題を解決するためのヒントとなりますのが、Saga パターンという考え方です。
TCCパターンとSagaパターンでマイクロサービスのトランザクションをまとめてみた - Qiita
Saga パターンについては、以下のページが参考になりました。
あと、こことか。
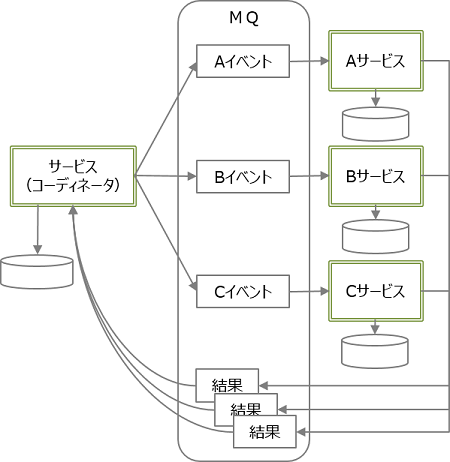
Kafka でこの Saga パターンを実現するためには、Kafka の Producer と Consumer 機能を、データを送信する側、受け取る側の両方から利用するようにして、Kafka を介してレスポンスを受け取れるようにする、という方式になります。具体的には以下のような感じです。
まず最初に、Kafka の Broker には、リクエストデータ用の Topic、レスポンスデータ用の Topic をそれぞれ設置した上で、
- データを送信する側のサービスからは、Kafka の Producer API を使って、このリクエストデータ用の Topic にデータ(=Kafka の用語で言うと「Message」)を送信
- データを受け取る側のサービスからは、Kafka の Consumer API を使って、リクエストデータ用の Topic から Message を受信
- データを受け取る側のサービスで処理を行ったのち、そのレスポンスデータを、Producer API を使って、レスポンスデータ用の Topic に送信
- データを送信する側のサービスでは、Consumer API を使って、レスポンスデータ用の Topic から Message を受信
これを図に表すと、以下のようになります。

若干、裏ワザ的な方式に思えなくもないのですが、ともかく、Kafka の仕組みを有効活用することで、レスポンスもちゃんと受け取ることができそうな気がしてきました。
モジュールを作る
Spring for Apache Kafka(spring-kafka)を使う
システム構成は決められたものの、これを実現するとなると、作りこむのはとても大変そう。
・・・と思っていたのですが、実は、ぜんぜんそんなことはありませんでした。
Spring Framework の上で使える、Spring for Apache Kafka(spring-kafka) というライブラリを用いて、びっくりするほど簡単に実現できたのでした。
ソースコード実装例は、こちらを参考にいたしました。
asbnotebook.com
以下、データ送信側サービス、データ受信側サービスのそれぞれのソースコードについて、詳しく見ていきます。
データ送信側サービスのモジュール作成
プロジェクト作成
今回は IntelliJ IDEA ツールから、Spring Initializr を用いて、Spring アプリケーションを作成します。
KafkaFrontendService という名前で、前述の「サービスA」に相当する、データ送信側サービスのプロジェクトを作成します。
このアプリケーションは Tomcat アプリケーションサーバで稼働し、
http://localhost:8080/kafka/lesson?message=あいうえお
といった URL でアクセスすることができる、REST API を提供します。
Dependencies の設定の部分では、Spring Web のほか、Spring for Apache Kafka を有効にします。

主なクラス、プロパティファイル
application.yml:
resources ディレクトリに配置する application.yml 定義ファイルには、以下のように、Kafka の Broker 接続情報、Topic 名、Consumer Group 名などを定義します。
spring: kafka: consumer: bootstrap-servers: localhost:9092,localhost:9093,localhost:9094 group_id: KafkaGroup1 enable_auto_commit: false key-deserializer: org.apache.kafka.common.serialization.LongDeserializer value-deserializer: org.apache.kafka.common.serialization.StringDeserializer properties: spring: json: trusted: packages: jp.co.iti.kafkafrontendservice producer: bootstrap-servers: localhost:9092,localhost:9093,localhost:9094 client_id: KafkaClient1 key-serializer: org.apache.kafka.common.serialization.LongSerializer value-serializer: org.apache.kafka.common.serialization.StringSerializer # user defined properties: kafka: request: topic: topic-request reply: topic: topic-response group: id: KafkaGroup1
KafkaConfig クラス:
KafkaConfig クラスでは、spring-kafka ライブラリが提供する ReplyingKafkaTemplate クラスのオブジェクトを定義します。
レスポンスデータの受け取り先となる、レスポンス用 Topic の名前も、ここで設定しています。
/** * Kafka 関連の各種設定を担当するクラス * 参考: * https://asbnotebook.com/2020/01/05/synchronous-request-reply-using-apache-kafka-spring-boot/ */ @Configuration public class KafkaConfig { // レスポンスを受けるための Consumer に指定するグループID @Value("${kafka.group.id}") private String groupId; // レスポンスデータが格納される topic 名 @Value("${kafka.reply.topic}") private String replyTopic; // 同期的な Request-Reply 形式でのメッセージ送受信を実現するための KafkaTemplate オブジェクト @Bean public ReplyingKafkaTemplate<Long, String, String> replyingKafkaTemplate( ProducerFactory<Long, String> pf, ConcurrentKafkaListenerContainerFactory<Long, String> factory) { ConcurrentMessageListenerContainer<Long, String> replyContainer = factory.createContainer(replyTopic); replyContainer.getContainerProperties().setMissingTopicsFatal(false); replyContainer.getContainerProperties().setGroupId(groupId); return new ReplyingKafkaTemplate<>(pf, replyContainer); } }
FrontendRestController クラス:
また、FrontendRestController クラスでは、REST API 呼び出しによって実行されるメソッドを定義します。
@RestController @RequestMapping(value = "/kafka") public class FrontendRestController { // private static final Logger logger = LoggerFactory.getLogger(FrontendRestController.class); // リクエストデータが格納される topic 名 @Value("${kafka.request.topic}") private String requestTopic; @Autowired private ReplyingKafkaTemplate<Long, String, String> replyingKafkaTemplate; // Gradle タスクの application > bootRun で起動した場合、 // http://localhost:8080/kafka/lesson?message=ABCDE // という URL で GET リクエストした場合に、当メソッドが呼び出される @GetMapping(value = "/lesson") public ResponseEntity<String> lesson( @RequestParam(value = "message", defaultValue = "defalut") String message) throws ExecutionException, InterruptedException, JsonProcessingException { // リクエストデータを作成 Request request = new Request(System.currentTimeMillis(), message); // JSON 文字列化 ObjectMapper mapper = new ObjectMapper(); String requestValue = mapper.writeValueAsString(request); logger.info("#### lesson. request: " + requestValue); // topic に格納するレコードを作成 ProducerRecord<Long, String> record = new ProducerRecord<>(requestTopic, null, null, requestValue); // リクエスト用 topic へのレコード push と、レスポンス用 topic からのレコード pull を実行 RequestReplyFuture<Long, String, String> future = replyingKafkaTemplate.sendAndReceive(record); ConsumerRecord<Long, String> consumerRecord = future.get(); Response response = new Response(request, consumerRecord.key(), consumerRecord.value(), consumerRecord.topic(), consumerRecord.partition(), consumerRecord.offset()); String responseValue = mapper.writeValueAsString(response); logger.info("#### lesson. response: " + responseValue); // 受け取ったレスポンスデータを REST API のレスポンスボディに設定して返す return new ResponseEntity<>(responseValue, HttpStatus.OK); } }
重要なのはこの部分。
RequestReplyFuture<Long, String, String> future =
replyingKafkaTemplate.sendAndReceive(record);
KafkaConfig クラスで定義した ReplyingKafkaTemplate クラスの sendAndReceive メソッドを用いて、
前述した図の中の 1、4 の処理を実現します。そうです。このメソッドの呼び出しだけで、です。

ソースコードの全体については、こちらをご参照ください。
データ受信側サービスのモジュール作成
プロジェクト作成
同様に、KafkaBackendService という名前で、前述の「サービスB(またはサービス C)」に相当する、データ受信側サービスのプロジェクトを作成します。
このアプリケーションは jar 形式でビルドして、
$ java -jar xxx.jar
といったコマンドから起動できるようにします。
Dependencies の設定の部分では、データ送信側サービスのプロジェクトと同様に、Spring for Apache Kafka を有効にします。

主なクラス
BackendService クラス:
BackendService クラスは、データ受信側サービスの本体となるクラスです。
今回の例では、受け取ったリクエストデータ文字列に「 done!」という文字列を加えて、レスポンスとして返すだけの、簡易的な内容となっています。
// データ受信側サービス(リクエストを Kafka から pull して、そのレスポンスを再度 Kafka に push する)クラス @Component public class BackendService { // private static final Logger logger = LoggerFactory.getLogger(BackendService.class); // @KafkaListener の指定により、指定の topic からのメッセージの pull を実行 // @SendTo の指定によって、当メソッドのレスポンスが、そのままレスポンス用の topic に push されることになる @KafkaListener(topics = "${kafka.request.topic}", groupId = "${kafka.group.id}") @SendTo("${kafka.reply.topic}") public String handle( @Payload String requestValue, @Headers Map<String, String> headers) throws JsonProcessingException { ObjectMapper mapper = new ObjectMapper(); Request request = mapper.readValue(requestValue, Request.class); // 受け取ったメッセージを元に加工した文字列を、レスポンスメッセージとして設定 Reply reply = new Reply(request.getIndex(), request.getMessage() + ". done!"); String replyValue = mapper.writeValueAsString(reply); logger.info("#### request messsage: " + requestValue + ", request header: " + headers.toString() + ", reply message: " + replyValue); return replyValue; } }
この handle メソッドに付与されている @KafkaListener、@SendTo アノテーションが重要な役割を担っていまして、
@KafkaListener(topics = "${kafka.request.topic}", groupId = "${kafka.group.id}") @SendTo("${kafka.reply.topic}") public String handle(
- @KafkaListener の指定によって、指定の Topic(この場合は、リクエストデータ用の Topic)に Message が追加されたことをトリガーとして、この handle メソッドが呼び出される。そのデータは、当メソッドの引数で受け取ることができる
- @SendTo の指定によって、この handle メソッドのレスポンス(戻り値)が、そのままレスポンスデータ用の Topic に送信される
という状態を実現することができるとのこと。(アノテーションすごい!)
これは、前述した図の中の 2、3 の処理を、このメソッドだけで実現している、ということになります。

spring-kafka ライブラリを用いることで、Saga パターンを、簡単に実現することができました。
ソースコードの全体については、こちらをご参照ください。
実行環境の準備
Kafka の起動
モジュールができあがったところで、これらを動かすための環境を準備します。
今回、Kafka(Apache Kafka) はローカルの Linux 環境上(正確には Docker コンテナ上)に構築しました。
Kafka の Broker(と ZooKeeper)の起動は、Apache Kafka に付属しているスクリプトを用いて行います。
$ cd {kafka インストール先ディレクトリ} $ bin/zookeeper-server-start.sh config/zookeeper1.properties & $ bin/zookeeper-server-start.sh config/zookeeper2.properties & $ bin/zookeeper-server-start.sh config/zookeeper3.properties & $ bin/kafka-server-start.sh config/server0.properties & $ bin/kafka-server-start.sh config/server1.properties & $ bin/kafka-server-start.sh config/server2.properties &
今回は検証用として、物理的に 1台のサーバ上に、Zookeeper:3、Broker:3 の構成としています。
Kafka 自体のインストールや、Broker、ZooKeeper の設定など、詳しくは Apache Kafka の Quickstart などをご参照ください。
Topic の作成
リクエストデータ用、レスポンスデータ用の Topic を作成します。Topic 名はそれぞれ "topic-request"、"topic-response" にしています。
$ bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 2 --partitions 3 --topic topic-request $ bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 2 --partitions 3 --topic topic-response
実行
データ受信側サービスの起動
リクエストデータ用、レスポンスデータ用の Topic が存在し、かつ、Kafka の Broker が稼働している状態で、
まずは、データ受信側サービス( KafkaBackendService )を起動します。
jar 形式にビルドしたあと、「 $ java -jar xxx.jar 」コマンドで起動することもできますが、今回は、IntelliJ IDEA ツール上から、Gradle の bootRun タスクで起動してみます。

正常に起動すると、リクエストデータ用 Topic( topic-request )への Message 追加を待ち受けている状態になります。
データ送信側サービスの起動
データ送信側サービス( KafkaFrontendService )も、IntelliJ IDEA ツール上から、Gradle の bootRun タスクで起動します。

こちらも正常に起動すると、アプリケーションサーバでモジュールが稼働すると同時に、レスポンスデータ用 Topic( topic-response )への Message 追加を待ち受けている状態になります。
サービスを呼び出す
ブラウザから「 http://localhost:8080/kafka/lesson?message=あいうえお 」にアクセスする(または curl コマンドで、同じ URL に GET リクエストする)と、
レスポンスデータが以下のように取得できました。「あいうえお. done!」という、データ受信側サービスでのデータ加工結果も、想定どおりに受け取れているようです。

Kafka のスクリプトを用いて、リクエストデータ用の Topic( topic-request )に格納されている Message を参照してみますと、
以下のように、データ送信側サービスから送った Message が、想定どおりに格納されていることが確認できます。
$ bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic topic-request --from-beginning {"index":1585272884603,"message":"あいうえお"}
また同じように、レスポンスデータ用の Topic( topic-response )を参照しますと、
以下のように、データ受信側サービスで加工した内容が、想定どおりに格納されていることが確認できます。
$ bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic topic-response --from-beginning {"index":1585272884603,"message":"あいうえお. done!"}
つまり、以下のような経路で、リクエスト・レスポンスデータを正しく受け渡すことができた、ということが確認できたのでした。

まとめ
マイクロサービス化を進めていく中でメリットも多く出てくるものの、こういった、サービス間の連携という課題を、どのように柔軟に解決していくか、のひとつの方法として、Kafka は有効だと感じました。