こんにちは、弊社 Intellijent Technorogy の、香川県のオフィスで活動している平田です。
日々の業務の中で、zoomで打ち合わせに参加し、メンバーのために打ち合わせ内容をメモして、お互いに認識齟齬が出ないように、打ち合わせの内容を議事録に起こして、共有を行い、、、他にもやらなくちゃいけないことがいろいろあるのに、議事録作成誰かやってくれないかな~というお悩みを持っている方も多くいらっしゃるのではないでしょうか?
今回はそんな悩みを少しでも解消したい!ということで、今話題のOpenAI社の ChatGPTと、同じくOpenAI社が提供しているWhisperというAPIを利用して、議事録の自動生成を行ってみたいと思います。
議事録自動生成に必要な機能
今回開発する「議事録自動生成」としては、最低限、次のような機能があればよいと考えました。
- 打ち合わせの内容を音声ファイルとして残す機能
- 音声ファイルをテキストファイルに変換する機能
- 変換したテキストファイルを受け取り、議事録を生成する機能
今回は議事録の自動生成がどのくらいの精度でできるのかを検証したい!ということをメインターゲットとしているので、実際にユーザが触る部分はPythonのTkinterで対象のファイルを選択できる程度の簡素な作りでいこうと思います。
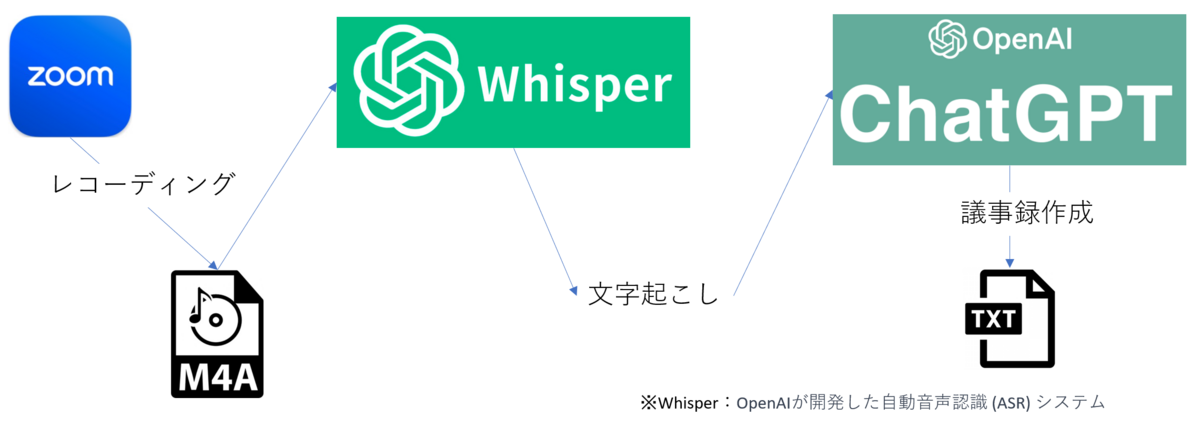
まず、1つ目の「打ち合わせの内容を音声ファイルとして残す」部分に関しては、zoomにレコーディング機能があるので、それを使っていきます。
標準機能なので、この部分は詳しい説明は省略します。
2つめの「音声ファイルをテキストファイルに変換する」部分については、OpenAI社のWhisper APIにより、変換を行ってもらおうと思います。
Whisperについての説明や精度については、後ろの章で紹介していきます。
3つめの「変換したテキストファイルを受け取り、議事録を生成する」部分については、ChatGPT APIを利用します。
議事録生成用のプロンプトと打ち合わせ内容が入ったテキストファイルを渡すことによって、議事録の生成を行ってもらおうと思います。
Whisperについて紹介
本題に入る前に
OpenAI社が提供しているWhisper APIについて初めて聞いたという方も居ると思うので、簡単に紹介しておこうと思います。
OpenAI社のWhisper APIは、音声をテキストに変換する高度な音声認識技術を提供するAPIです。
このシステムは、多くの言語を理解し、さまざまな音声環境下での精確な文字起こしを可能にします。
Whisper APIを利用することで、独自のアプリケーションやサービスに音声認識機能を簡単に統合できるようになります。
Whisper APIの利用料金は1分あたり0.006ドルとなっており、利用上限に関しては、入力ファイルのサイズが25MB以下である必要があります。
Whisperの性能について
もう一つ、本題に入る前に
議事録自動生成を実際に行っていく前に、Whisperの性能を確認しておきます。
性能の確認方法としては、以下で進めていきます。
・文字起こしを行うためのスクリプトを考える
・スクリプトに合わせて、zoomでレコーディングを行う
・レコーディングした内容をWhisperで文字起こしを行う
・始めに作成したスクリプトと文字起こしを行った結果を比較
まずは2分程度の仮想の打ち合わせの内容を考えていきます。
ここの部分についても、ChatGPTを使っていきます。
ChatGPTに5人で2分程度の打ち合わせを行っている内容を生成してもらいました。
生成してもらった内容がこちら

この生成してもらったスクリプトの内容をzoomでレコーディングしました。
そして、Whisperにより文字起こしを行った内容がこちら

私がInstagramを発音するときに噛んでしまい、インストグラムになっている部分と「有名人の力を借りるのも一つの方法です」の部分が「イメージの力を借りるのも必要な方法です」になっている部分を除くとあとは完璧に文字起こししてくれていました。
正解率は99%となっています。
かなり精度がいいことが分かりましたので、このまま議事録作成まで進んでいきたいと思います。
アプリを仕上げる
ここから本題に戻って、議事録自動生成のアプリを仕上げていきます。
まずは音声ファイルを渡し、WhisperのAPIを呼び出して、文字起こしを行い、テキストファイルに変換するところから作っていこうと思います。
以下のソースコードを見てもらえばわかるように、テキストファイルに変換するところは
3行ほどのコードで作れてしまうほどシンプルな形となっています。
これで、Whisperによる文字起こしまでは完了です。
import openai import os import tkinter.filedialog openai.api_key = os.getenv("OPENAI_API_KEY") # 入力ファイルのパスと出力フォルダのパスを指定 # whisper は25MB以上のファイルは対応できていない filetypes = [('m4a files', '*.m4a'),('mp4 files', '*.mp4')] input_file_path = tkinter.filedialog.askopenfilename(filetypes = filetypes, initialdir='./') if not input_file_path: print("ファイルが選択されませんでした。") exit() output_folder_path = './output_folder' # 音声ファイルが選択されたので、文字起こしを行っていく。 audio_file=open(input_file_path, "rb") transcript=openai.Audio.transcribe("whisper-1", audio_file) transcription=str(transcript["text"]) # 文字起こしした結果をtextファイルに保存していく # 結果をテキストファイルに保存 filepath = os.path.join(output_folder_path, "kaigi.txt") with open(filepath, "w") as file: for item in transcription: file.write(str(item)) print("処理結果をkaigi.txtに保存しました。")
つぎに、ChatGPTのAPIを利用して、テキストファイルから議事録の生成部分を作っていきます。
議事録作成のプロンプト部分は各議事録のフォーマットに合わせて工夫して頂ければと思います。
今回はこんな感じで日付、参加メンバー、打ち合わせの目的、結果、持ち帰り事項、内容についての取りまとめをChatGPTにお願いする形で準備してみました。
実際に議事録生成する部分は5行ほどのコーディングでできてしまう感じです。
今回はモデルとしてgpt-3.5-turboを選択しています。
これで議事録の自動生成の準備が整ったので、実行をしていきたいと思います。
import openai import os openai.api_key = os.getenv("OPENAI_API_KEY") system_template = """あなたは議事録作成のプロです。 この打ち合わせの議事録作成を行なってください。 渡された情報の中から判別できる範囲で以下の項目を埋めて議事録の作成を行なってください。 - 日付 - 参加メンバー - 打ち合わせの目的 - 結果もしくは持ち帰り事項 - 打ち合わせの内容 """ with open('./output_folder/0913kaigi.txt', 'r') as file: user_content = file.read() completion = openai.ChatCompletion.create( model="gpt-3.5-turbo", messages=[ {"role":"system", "content": system_template}, {"role":"user", "content": user_content} ] ) response_text = completion.choices[0].message.content print(response_text)
アプリの実行
実際に出来上がったものを使って議事録の生成を行ってみたいと思います。
まずはサンプルで用意していた2分程度の音声ファイルから議事録を生成していきます。
出来上がったものがこちら

日付は会話の中に出てこなかったので、記載できていませんが、参加メンバーや打ち合わせの目的、結果や持ち帰り事項など、必要な情報をすべて抽出して議事録の作成を行ってくれました。
議事録が生成されるまでの時間も2,3分といったところで、人が時間をかけて作るよりも断然タイパは良いモノとなっていました。
また、内容もおかしなところはなく、なかなかの出来となっています。
お見せすることはできないのですが、実際に社内で打ち合わせを行っているところを10分ほどレコーディングして、自動議事録生成を行ってみましたが、その内容もしっかりとまとまったものが生成されており、十分実用レベルであると判断しました。
利用可能時間、利用料金
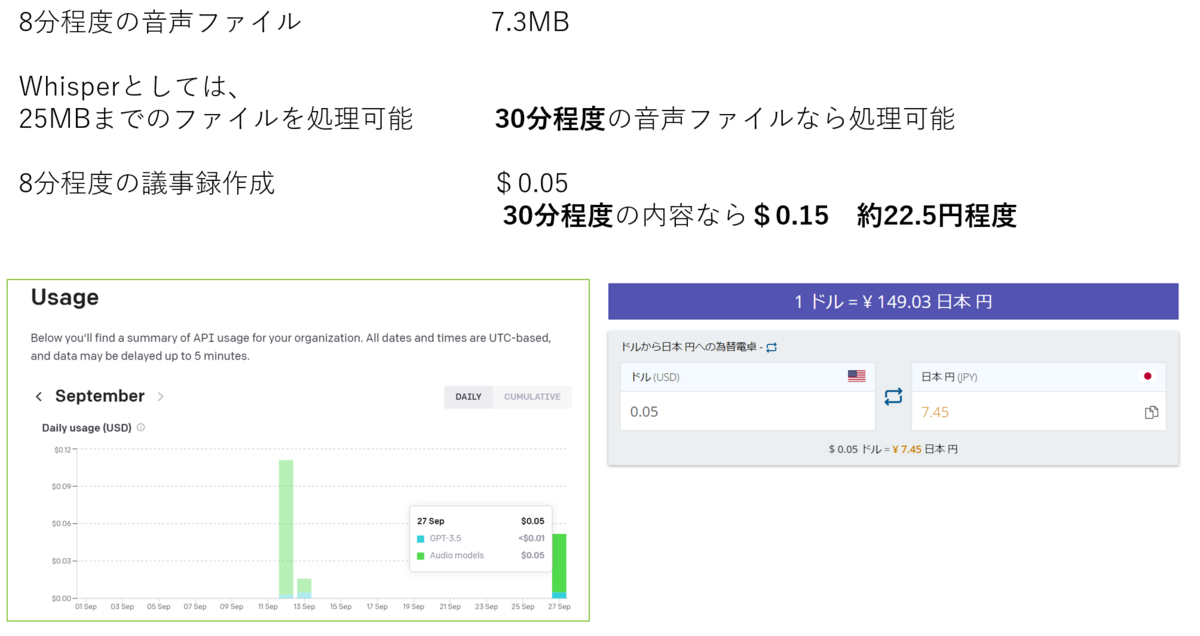
8分程度の音声ファイルのファイルサイズを確認すると7.3MB程度でした。
利用可能時間については、Whisperの変換上限がいまのところ25MBまでということで、そこから計算すると30分程度の音声ファイルなら処理可能となっています。
音声ファイルのビットレートを下げることで、より長い会話を文字起こしすることも可能ですが、ファイルの品質が低下すると、その分、文字起こしの精度や信頼性も低下するのであまりお勧めできないかなという感じです。
また、ファイルを分割して文字起こしするという方法もあるので、30分以上の音声ファイルの場合、25MB未満になるようにファイルを分割してWhisperに渡すことで解決する方法もありそうです。
Whisperの文字起こしは前後の文脈からこれが最適と思われる言葉をチョイスしているようなので、分割するポイントによっては、前半ではうまく識別できていた言葉が、後半ではうまく識別できず、文字起こしがうまくいかないということもあるので、注意が必要です。
利用料金については、上を見ていただくとわかるように8分程度の音声ファイルからの議事録作成で0.05ドル、日本円では7.5円程度となっていました。
こちらも30分程度の音声ファイルからの議事録作成を行うと、大体23円程度となります。人が議事録を作成するよりも確実に安価にできるので、利用していく価値は十分あるのではないかと思います。
おまけ
今回の議事録自動作成のコーディングをChatGPTにお任せしたらどうなるかなというのも試してみました。
ChatGPTに依頼したプロンプトは以下となります。
openaiのChatGPTのAPIとWhisperのAPIを利用して 議事録の作成を行ってくれるpythonプログラムを作成したいです。 流れとしては以下のように考えています。 1.zoomで会議内容をレコーディング。m4aファイルとして出力 2.m4aファイルの内容をwhisper APIを使用して文字起こし、結果はoutput.txtとして出力 3.output.txtに出力された内容をChatGPTのAPIを使って議事録作成 4.自動生成された議事録はgiji.txtとして出力する APIキーは環境変数に設定されているものとします。 この内容でコーディングしたいので、サンプルプログラムを作ってください。
そうすると1,2分で以下のようなベースコードの生成を行ってくれました。
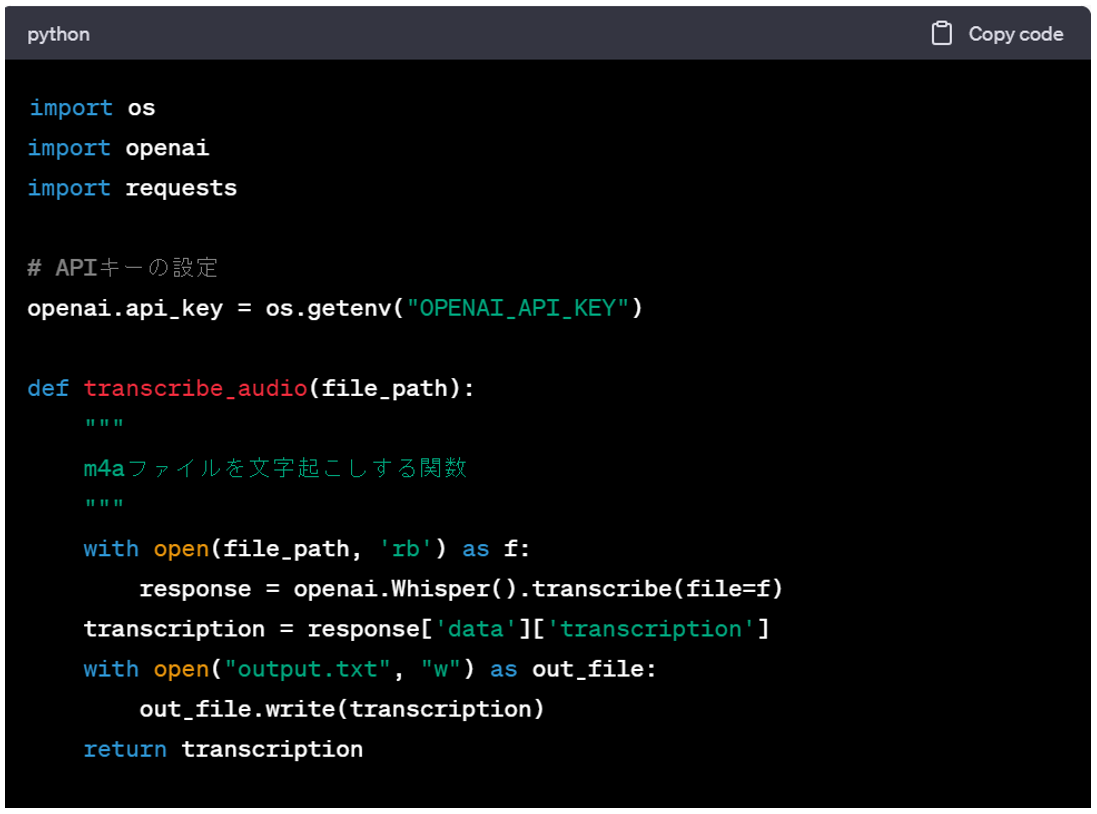
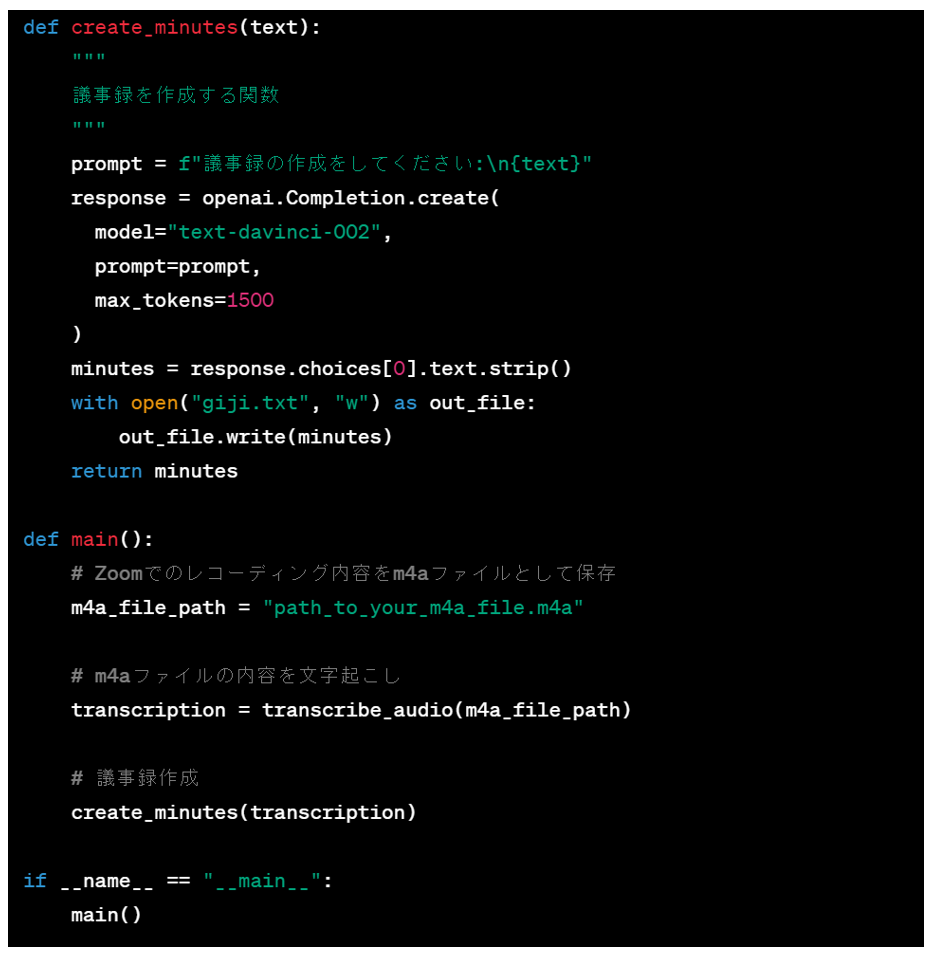
一発で完璧なソースが生成されるわけではないですが、ここまでベースを組んでくれたらあとは自分でコードをカスタマイズしていけばいいでしょう。
もしくはChatGPTにさらにリクエストを繰り返し行い、完成までもっていくことも可能だと思います。
開発者側がChatGPTが生成してくれたソースコードの内容を理解して、正しく指示を出していくことができたら、ほぼコーディングはChatGPTなどの生成系AIにお任せできる未来もそう遠くないかもしれません。